









服務熱線
0755-83044319

發布時間:2024-06-20作者來源:薩科微瀏覽:3259
今年3月份,英偉達發布了Blackwell B200,號稱全球最強的 AI 芯片。它與之前的A100、A800、H100、H800有怎樣的不同?

1.英偉達GPU架構演進史
我們先回顧一下,歷代英偉達AI加速卡的算力發展史:
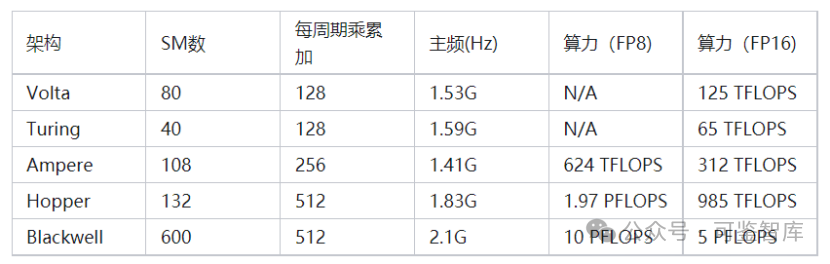
[敏感詞]代AI加速卡叫Volta ,是英偉達[敏感詞]次為AI運算專門設計的張量運算(Tensor Core)架構。
第二代張量計算架構叫圖靈(Turing),代表顯卡T4。
第三代張量運算架構安培(Ampere),終于來到我們比較熟悉的A100系列顯卡了。
在芯片工藝升級的加持下,單卡SM翻倍到了108個,SM內的核心數和V100相同,但是通過計算單元電路升級,核心每一個周期可以完成256個浮點數乘累加,是老架構的兩倍。加入了更符合當時深度學習需要的8位浮點(FP8)運算模式,一個16位浮點核心可以當作2個8位浮點核心計算,算力再翻倍。主頻稍有下降,為1.41GHz。因此最后,A100顯卡的算力達到了V100的近5倍,為108*8*256*1.41GHz*2 =624 TFLOPS (FP8)。

Ampere 架構
第四代架構Hopper,也就是英偉達去年剛發布、OpenAI大語言模型訓練已經采用、且因算力問題被禁運的H100系列顯卡。
該顯卡的SM數(132個)相較前代并未大幅提升,但是因為全新的Tensor Core架構和異步內存設計,單個SM核心一個周期可以完成的FP16乘累加數再翻一倍,達到512次。主頻稍微提高到1.83GHz,最終單卡算力達成驚人的1978 Tera FLOPS(FP8),也即首次來到了PFLOPS(1.97 Peta FLOPS)領域。

Hopper 架構
第五代架構Blackwell,在這個算力天梯上又取得了什么樣的進展呢?根據公開的數據,如果采用全新的FP4數據單元,GB200在將能在推理任務中達到20 Peta FLOPS算力。將其還原回FP8,應該也有驚人的10 PFLOPS,這相對H100提升將達到5倍左右。
公開數據顯示,Blackwell的處理器主頻為2.1GHz。假設架構沒有大幅更新,這意味著Blackwell將有600個SM,是H100的接近4倍。Blackwell有兩個Die,那么單Die顯卡的SM數也達到了H100的2倍。
可以說,每一代架構的升級,單個GPU算力實現數倍增長。這里,我們將從Volta架構至今的算力天梯進展圖列表如下,方便大家查閱:
2. A100 VS A800,H100 VS H800
為什么有A100還要A800呢?先說說背景
2022年10月,美國出臺了對華半導體出口限制新規,其中就包括了對于高性能計算芯片對中國大陸的出口限制。并且以NVIDIA的A100芯片的性能指標作為限制標準;即同時滿足以下兩個條件的即為受管制的高性能計算芯片:
(1)芯片的I/O帶寬傳輸速率大于或等于600 Gbyte/s;
(2)“數字處理單元 原始計算單元”每次操作的比特長度乘以TOPS 計算出的的算力之和大于或等于4800TOPS。
這也使得NVIDIA A100/H100系列、AMD MI200/300系列AI芯片無法對華出口。
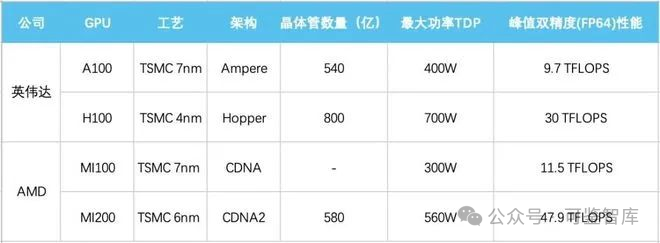
為了在遵守美國限制規則的前提下,同時滿足中國客戶的需求,英偉達推出A100的替代產品A800。從官方公布的參數來看,A800主要是將NVLink的傳輸速率由A100的600GB/s降至了400GB/s,其他參數與A100基本一致。
2023年,英偉達發布了新一代基于4nm工藝,擁有800億個晶體管、18432個核心的H100 GPU。同樣,NVIDIA也推出了針對中國市場的特供版H800。
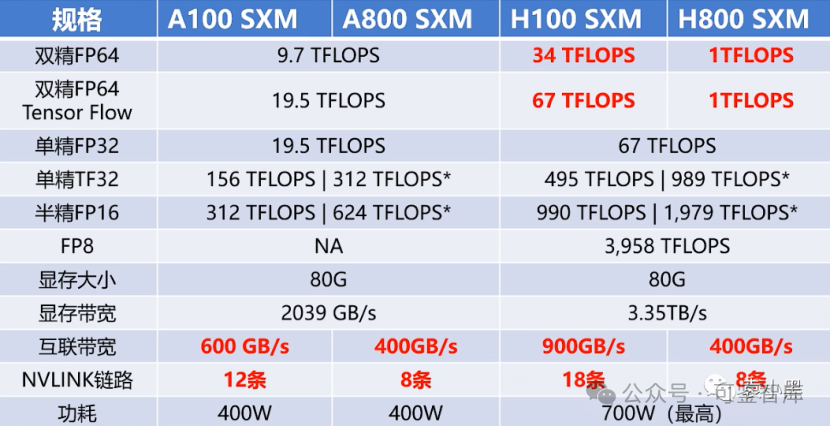
實際上,A800在互聯帶寬,即 N 維鏈和鏈路部分做了調整,從 A100的600G/s 降到了400G/s。但是在其他方面,如雙精、單精、半精等在 AI 算力方面并沒有變化。
相對而言,H800則做了較大的調整。它不僅在鏈路方面進行了調整,保持了 8條的 NVlink,雙向互聯帶寬仍為400G,并且對雙精度算力進行了幾乎歸零的處理。這對 HPC 領域來說非常關鍵,因為 FP64的雙精度算力直接減少到了一,也就是說幾乎不讓你使用了。
接下來,我們來看一下閹割后對哪些業務有很大的影響。
大模型戰場: A800閹割后降低了大模型的訓練的效率, A800 SXMM 主要是 GPU 卡之間的數據傳輸效率降低,帶寬降低 33%。以 GPT-3 為例, 規模達到 1750 億, 需要多張 GPU 組合訓練, 如果帶寬不足則使性能下降約 4 成 (出現 GPU 算力高需要等待數據的情況), 考慮到 A 800 和 H 800 性價比, 國內用戶還是傾向于 A 800。由于閹割后的 A800和 H800在訓練效率上有所下降,因為他們需要在卡之間交互訓練過程中的一些數據,所以他們的傳輸速率的降低導致了他們的效率的降低。
HPC 領域: A800 和 A100 在雙精方面算力一致, 所以在高性能科學計算領域沒有影響, 但是可惡的是 H800 直接將雙精算力直接降到了 1 TFLOPS, 直接不讓用了;這對超算領域的影響還是很大的。
所以影響是顯而易見的,在 AIGC 、HPC 領域中,國內的一些企業可能會被國外的企業拉開一定的差距。這是可預見到的,所以說在一些情況下,如果我們要計算能力要達到一定的性能,它的投入可能會更高。此外,我們只能從國外借殼,通過成立分公司的方式,把大模型訓練的任務放在國外,我們只是把訓練好的成果放在國內去用就可以了。但是,這只是一種臨時性的方案,特別是面臨數據出境風險。
3.后話
眾所周知,目前美國對中國的芯片限制越來越嚴格,在GPU上面也是如此。
2022年美國禁掉了高性能GPU芯片,包括A100、H100等,而2023年又禁掉了A800、H800、L40、L40S,甚至連桌面端顯卡RTX 4090都禁了。
因此,國內科技企業也積極調整產業策略,為未來減少使用英偉達芯片做準備,從而避免不斷調整技術以適應新芯片的巨大代價。阿里和騰訊等云廠商將一些先進的半導體訂單轉移給華為等本土公司,并更多地依賴其內部開發的芯片,百度和字節跳動等企業也采取了類似措施。顯然,國內企業選擇“英偉達+自研+國產芯片”三管齊下進行探路。
免責聲明:本文采摘自網絡,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2022 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號-1
