









服務熱線
0755-83044319

發布時間:2022-03-18作者來源:薩科微瀏覽:2615
一、3D 封裝將成為主要工藝
轉自:智東西
近日,中國臺灣工業技術研究院研究總監 Yang Rui 預測,臺積電將在芯片制造業再占主導地位五年,此后 3D 封裝將成為主要工藝挑戰。
過去十年各種計算工作負載飛速發展,而摩爾定律卻屢屢被傳將走到盡頭。面對更家多樣化的計算應用需求,為了將更多功能 " 塞 " 到同一顆芯片里,先進封裝技術成為持續優化芯片性能和成本的關鍵創新路徑。
臺積電、英特爾、三星均在加速 3D 封裝技術的部署。今年 8 月,這三大芯片制造巨頭均亮出,使得這一戰場愈發硝煙四起。
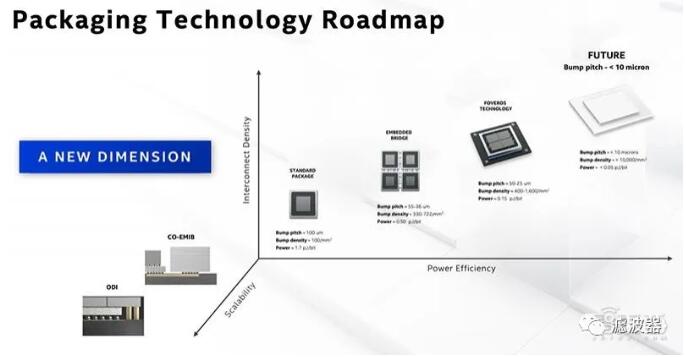
▲英特爾封裝技術路線圖
通過三大芯片制造巨頭的先進封裝布局,我們可以看到在接下來的一年,3D 封裝技術將是超越摩爾定律的重要殺手锏。
一、先進封裝:將更多功能塞進一顆芯片
此前芯片多采用 2D 平面封裝技術,但隨著異構計算應用需求的增加,能將不同尺寸、不同制程工藝、不同材料的芯片集成整合的 3D 封裝技術,已成為兼顧更高性能和更高靈活性的必要選擇。
從[敏感詞] 3D 封裝技術落地進展來看,英特爾 Lakefield 采用 3D 封裝技術 Foveros,臺積電的 3D 封裝技術 SoIC 按原計劃將在 2021 年量產,三星的 3D 封裝技術已應用于 7nm EUV 芯片。
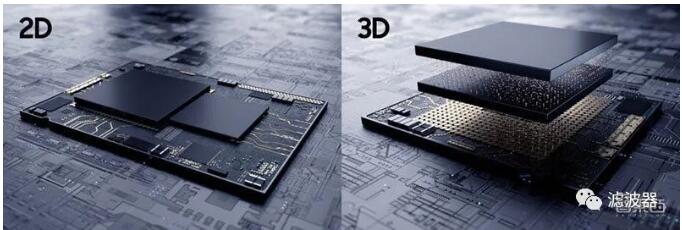
為什么要邁向先進封裝技術?主要原因有二點,一是迄今處理器的大多數性能限制來自內存帶寬,二是生產率提高。
一方面,存儲帶寬的開發速度遠遠低于處理器邏輯電路的速度,因此存在 " 內存墻 " 的問題。
在傳統 PCB 封裝中,走線密度和信號傳輸速率難以提升,因而內存帶寬緩慢增長。而先進封裝的走線密度短,信號傳輸速率有很大的提升空間,同時能大大提高互連密度,因而先進封裝技術成為解決內存墻問題的主要方法之一。
另一方面,高性能處理器的體系架構越來越復雜,晶體管的數量也在增加,但先進的半導體工藝仍然很昂貴,并且生產率也不令人滿意。
在半導體制造中,芯片面積越小,往往成品率越高。為了降低使用先進半導體技術的成本并提高良率,一種有效的方法是將大芯片切分成多個小芯片,然后使用先進的封裝技術將它們連接在一起。
在這一背景下,以臺積電、英特爾、三星為代表的三大芯片巨頭正積極探索 3D 封裝技術及其他先進封裝技術。
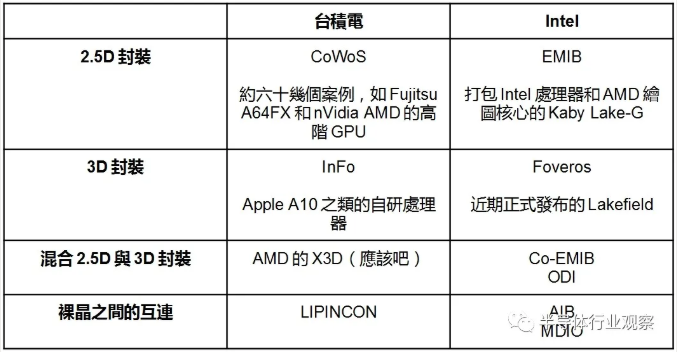
二、臺積電的3D封裝組合拳
今年 8 月底,臺積電推出 3DFabric 整合技術平臺,旨在加快系統級方案的創新速度,并縮短上市時間。
臺積電 3DFabric 可將各種邏輯、存儲器件或專用芯片與 SoC 集成在一起,為高性能計算機、智能手機、IoT 邊緣設備等應用提供更小尺寸的芯片,并且可通過將高密度互連芯片集成到封裝模塊中,從而提高帶寬、延遲和電源效率。
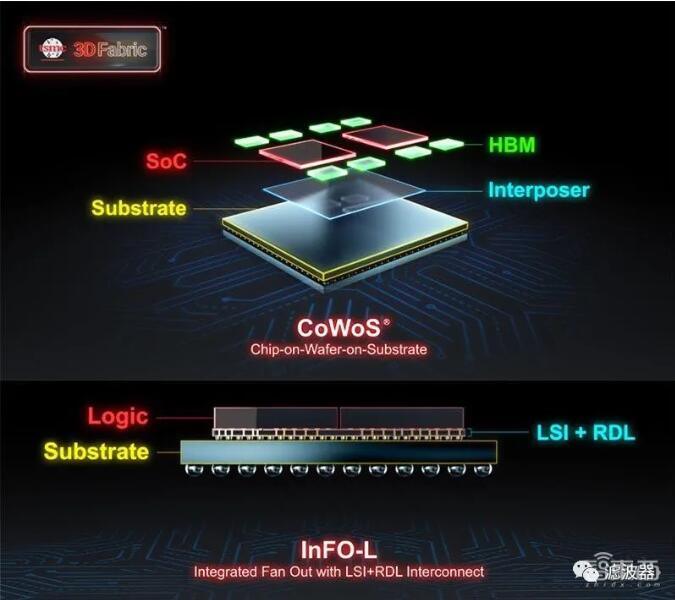
3DFabric 由臺積電前端和后端封裝技術組成。
前端 3D IC 技術為臺積電 SoIC 技術,于 2018 年首次對外公布,支持 CoW(Chip on Wafer)和 WoW(Wafer on Wafer)兩種鍵合方式。
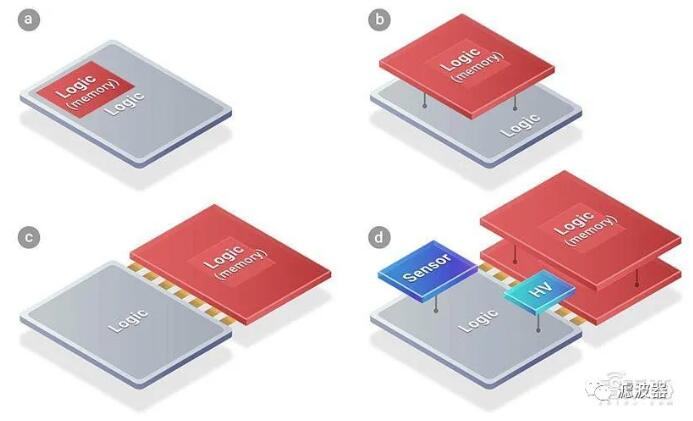
▲ a 為芯片分割前的 SoC;b、c、d 為臺積電 SoIC 服務平臺支持的多種分區小芯片和重新集成方案
通過采用硅穿孔(TSV)技術,臺積電 SoIC 技術可達到無凸起的鍵合結構, 從而可將不同尺寸、制程、材料的小芯片重新集成到一個類似 SoC 的集成芯片中,使最終的集成芯片面積更小,并且系統性能優于原來的 SoC。

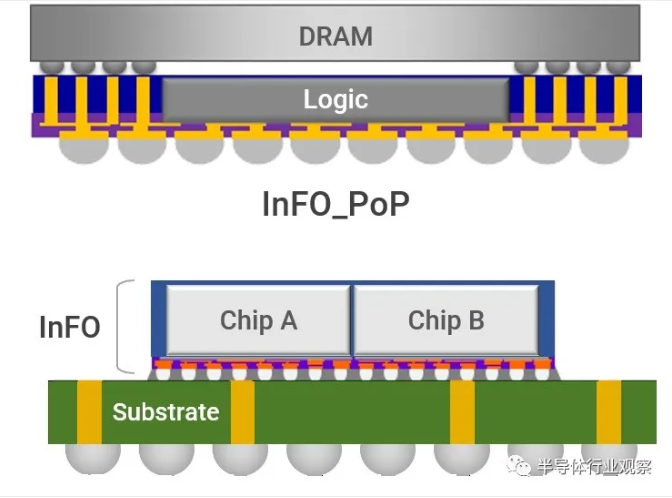
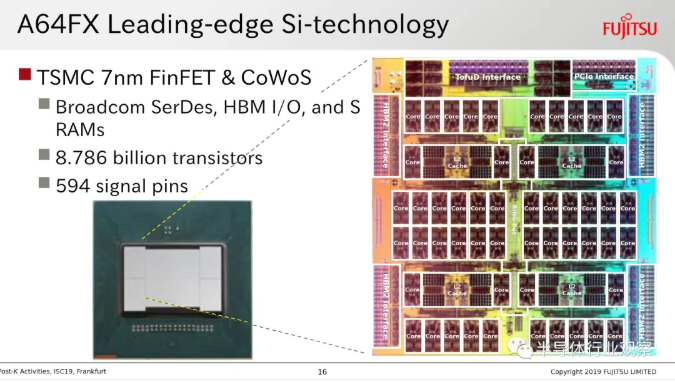
臺積電后端技術包括 CoWoS(Chip on Wafer on Substrate)和 InFO(Integrated Fan-out)系列封裝技術,已經廣泛落地。例如今年全球 TOP 500 超算榜排名[敏感詞]的日本超算 " 富岳 " 所搭載的 Fujitsu A64FX 處理器采用了臺積電 CoWoS 封裝技術,蘋果手機芯片采用了臺積電 InFO 封裝技術。
此外,臺積電擁有多個專門的后端晶圓廠,負責組裝和測試包括 3D 堆疊芯片在內的硅芯片,將其加工成封裝后的設備。
這帶來的一大好處是,客戶可以在模擬 IO、射頻等不經常更改、擴展性不大的模塊上采用更成熟、更低成本的半導體技術,在核心邏輯設計上采用[敏感詞]的半導體技術,既節約了成本,又縮短了新產品的上市時間。
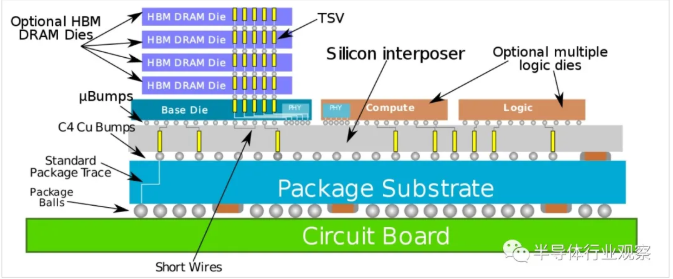
臺積電 3DFabric 將先進的邏輯、高速存儲器件集成到封裝模塊中。在給定的帶寬下,高帶寬內存(HBM)較寬的接口使其能以較低的時鐘速度運行,從而減少功耗。
如果以數據中心規模來看,這些邏輯和 HBM 器件節省的成本十分可觀。
三、英特爾用"分解設計"策略打出差異化優勢
和臺積電相似,英特爾也早已在封裝領域布局了多種維度的先進封裝技術。
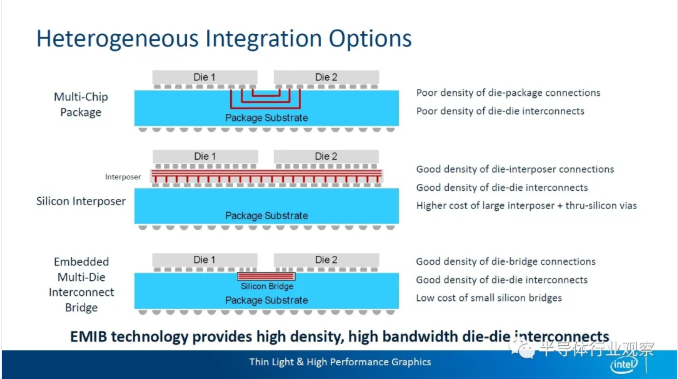
在 8 月 13 日的 2020 年英特爾架構日上,英特爾發布一個全新的混合結合(Integrated Fan-out)技術,使用這一技術的測試芯片已在 2020 年第二季度流片。
相比當前大多數封裝技術所使用的熱壓結合(Thermocompression bonding)技術,混合結合技術可將凸點間距降到 10 微米以下,提供更高互連密度、更高帶寬和更低功率。

▲英特爾混合結合技術
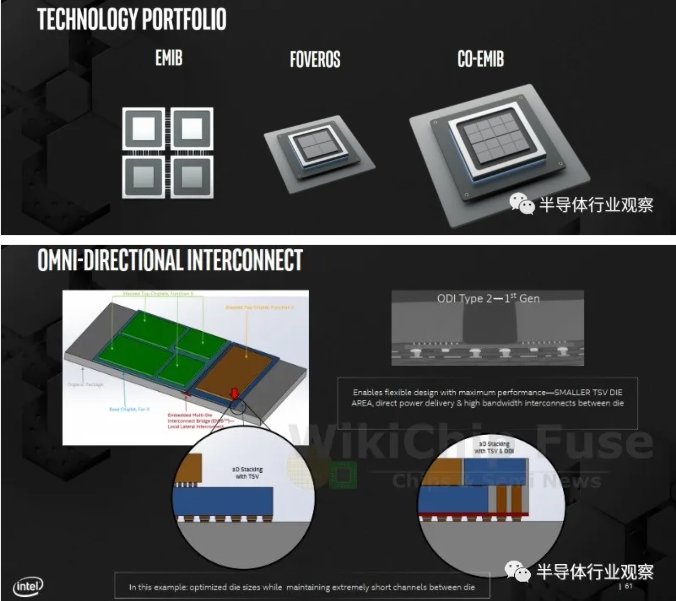
此前英特爾已推出標準封裝、2.5D 嵌入式多互連橋(EMIB)技術、3D 封裝 Foveros 技術、將 EMIB 與 Foveros 相結合的 Co-EMIB 技術、全方位互連(ODI)技術和多模 I/O(MDIO)技術等,這些封裝互連技術相互疊加后,能帶來更大的可擴展性和靈活性。
據英特爾研究院院長宋繼強介紹:" 封裝技術的發展就像我們蓋房子,一開始蓋的是茅廬單間,然后蓋成四合院,最后到高樓大廈。以 Foveros 3D 來說,它所實現的就是在建高樓的時候,能夠讓線路以低功率同時高速率地進行傳輸。"
他認為,英特爾在封裝技術的優勢在于,可以更早地知道未來這個房子會怎么搭,也就是說可以更好地對未來芯片進行設計。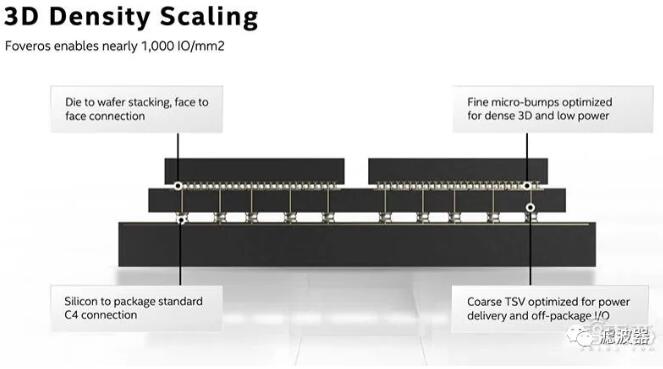
面向未來的異構計算趨勢,英特爾推出 " 分解設計(Digression design)" 策略,結合新的設計方法和先進的封裝技術,將關鍵的架構組件拆分為仍在統一封裝中單獨晶片。
也就是說,將原先整個 SoC 芯片 " 化整為零 ",先做成如 CPU、GPU、I/O 等幾個大部分,再將 SoC 的細粒度進一步提升,將以前按照功能性來組合的思路,轉變為按晶片 IP 來進行組合。
這種思路的好處是,不僅能提升芯片設計效率、減少產品化的時間,而且能有效減少此前復雜設計所帶來的 Bug 數量。
" 原來一定要放到一個晶片上做的方案,現在可以轉換成多晶片來做。另外,不僅可以利用英特爾的多節點制程工藝,也可以利用合作伙伴的工藝。" 宋繼強解釋。
這些分解開的小部件整合起來之后,速度快、帶寬足,同時還能實現低功耗,有很大的靈活性,將成為英特爾的一大差異性優勢。
四、三星首秀3D封裝技術,可用于7nm工藝
除了臺積電和英特爾外,三星也在加速其 3D 封裝技術的部署。
8 月 13 日,三星也公布了其 3D 封裝技術為 "eXtended-Cube",簡稱 "X-Cube",通過 TSV 進行互連,已能用于 7nm 乃至 5nm 工藝。
據三星介紹,目前其 X-Cube 測試芯片可以做到將 SRAM 層堆疊在邏輯層上,可將 SRAM 與邏輯部分分離,從而能騰出更多空間來堆棧更多內存。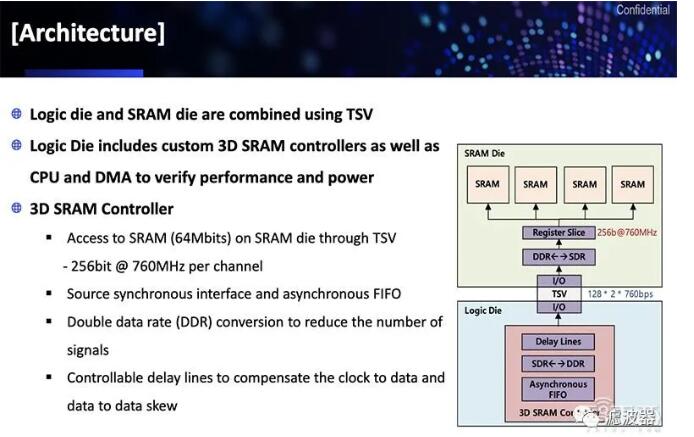
▲三星 X-Cube 測試芯片架構
此外,TSV 技術能大幅縮短裸片間的信號距離,提高數據傳輸速度和降低功耗。
三星稱,該 3D 封裝技術在速度和功效方面實現了重大飛躍,將幫助滿足5G、AI、AR、VR、HPC、移動和可穿戴設備等前沿應用領域的嚴格性能要求。
結語:三大芯片巨頭強攻先進封裝
可以看到,在 2020 年,圍繞 3D 封裝技術的戰火繼續升級,臺積電、英特爾、三星這三大先進芯片制造商紛紛加碼,探索更廣闊的芯片創新空間。
盡管這些技術方法的核心細節有所不同,但殊途同歸,都是為了持續提升芯片密度、實現更為復雜和靈活的系統級芯片,以滿足客戶日益豐富的應用需求。
而隨著制程工藝逼近極限,以及應用需求的持續多元化,未來芯片制造商除了要解決散熱等技術挑戰外,還有望推進來自不同廠商的先進封裝技術的融合。
二、芯片巨頭決戰先進封裝
轉自:半導體行業觀察
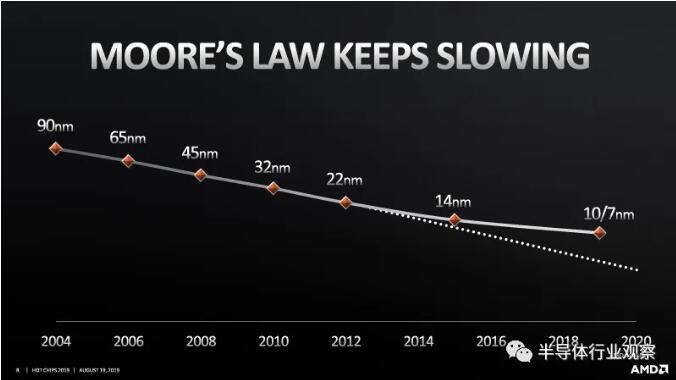
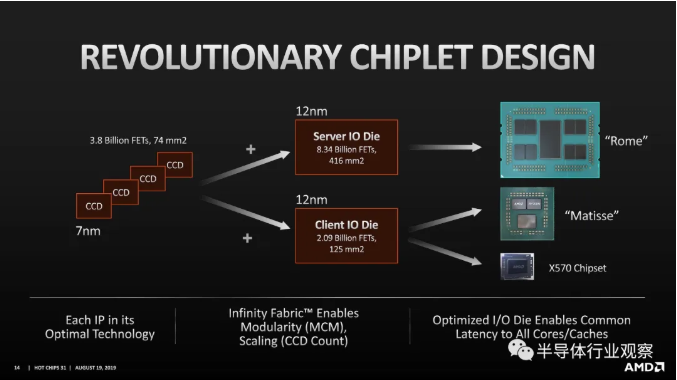
發展方興未艾的先進封裝技術


超級電腦用的系統單芯片并非IBM 和Fujitsu 的專利


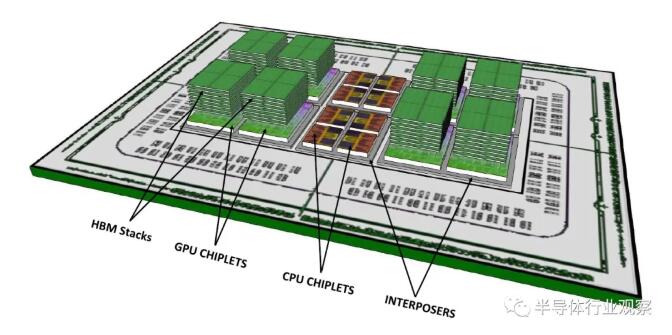
32 個CPU 核心(當時是8 顆4 核心CCD)。
8 顆32 個GPU CU,總計256 CU 與16,384 個串流處理器(那時預定是GCN 第五代的Vega,看來將會推進到CDNA)。
8 塊4GB HBM2 記憶體堆疊。
時脈1GHz 時,雙倍浮點精確度理論效能為16TeraFlops,如十萬顆組成超級電腦,就是1.6ExaFlops,預估耗電量為20MW。
AMD 在2015 年7 月IEEE Micro 專文,表示32 個CPU 核心、320 個時脈1GHz 的GPU CU(20,480 個串流處理器)、3TB/s 記憶體頻寬、160W 功耗,是能耗比[敏感詞]的組態,總之實際的產品一定會變。
EHP 和X3D 的技術資產會「推己及人」到Zen 3 世代EPYC 處理器「Milan」的可怕傳言(像10 顆CCD 湊80 核心或塞HBM2 當L4 之類的),一直沒有停過。
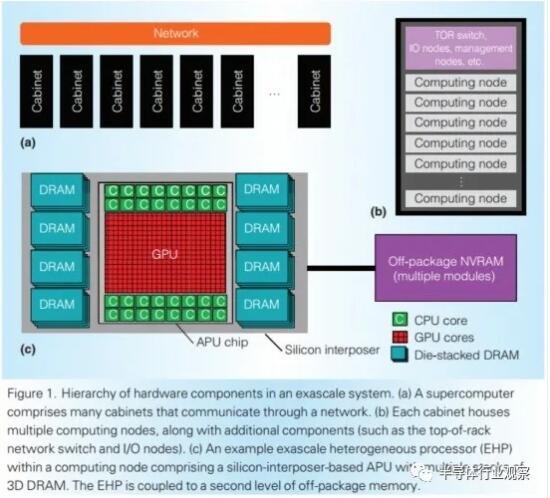
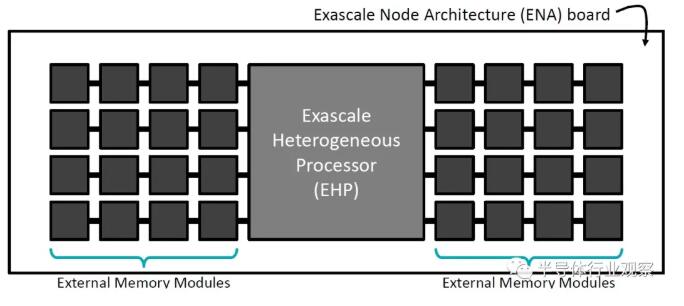
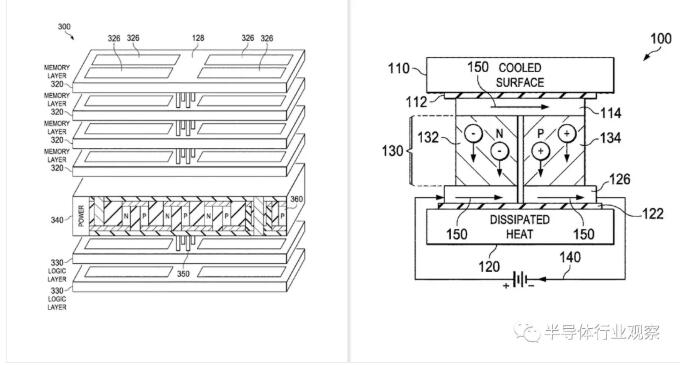
同場加映:nVidia 也沒吃飽閑著
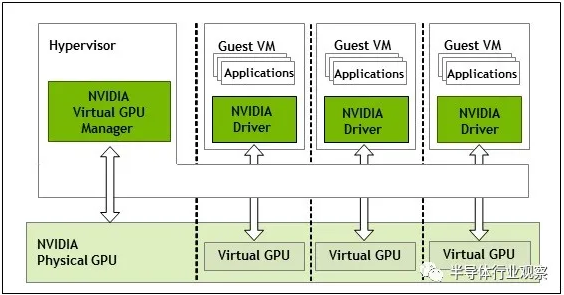
弦外之音:GPU 驅動程式開源的沖擊
技術的發展跟著應用的需求走,這恐怕也將會注定AMD 靠著「超級電腦APU」反攻高效能運算市場的企圖能否悲愿成就的鎖鑰。
免責聲明:本文轉載自“濾波器”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
公司電話:+86-0755-83044319
傳真/FAX:+86-0755-83975897
郵箱:1615456225@qq.com
QQ:3518641314 李經理
QQ:332496225 丘經理
地址:深圳市龍華新區民治大道1079號展滔科技大廈C座809室
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2022 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號-1
